Introduction
Modern computing systems are expected to handle increasingly large workloads while remaining fast, responsive, and scalable. Whether in:
Operating systems
Cloud computing
Databases
Web servers
Distributed systems
Networking
Mobile applications
performance optimization is a critical concern.
When evaluating system performance, two of the most important metrics are:
Throughput
Latency
Although these terms are closely related, they measure very different aspects of system behavior.
Many students and engineers confuse throughput and latency because improving one does not always improve the other. In fact, optimizing systems often requires balancing trade-offs between:
Fast individual response times
High overall processing capacity
Understanding throughput and latency is essential for:
Operating systems
System design
Cloud infrastructure
Distributed computing
Performance engineering
Scalability analysis
What is Throughput?
Throughput measures:
How much work a system can complete within a given amount of time.
It represents:
Processing capacity
Overall productivity of system
Core Idea
Throughput measures total work completed per unit time
Examples of Throughput
Requests processed per second
Transactions completed per minute
Packets transferred per second
Jobs executed per hour
Example
Suppose server handles:
10,000 requests per second
This indicates:
High throughput
Important Insight
Throughput focuses on overall system productivity rather than individual request speed
What is Latency?
Latency measures:
How long it takes to complete a single operation or request.
It represents:
Delay
Response time
Waiting time
Core Idea
Latency measures the time required to complete an individual task
Examples of Latency
Time to open webpage
Database query response time
Disk access delay
Network packet delay
Example
Suppose webpage loads in:
50 milliseconds
This indicates:
Low latency
Important Insight
Latency focuses on responsiveness experienced by individual users or operations
Visualization of Throughput vs Latency
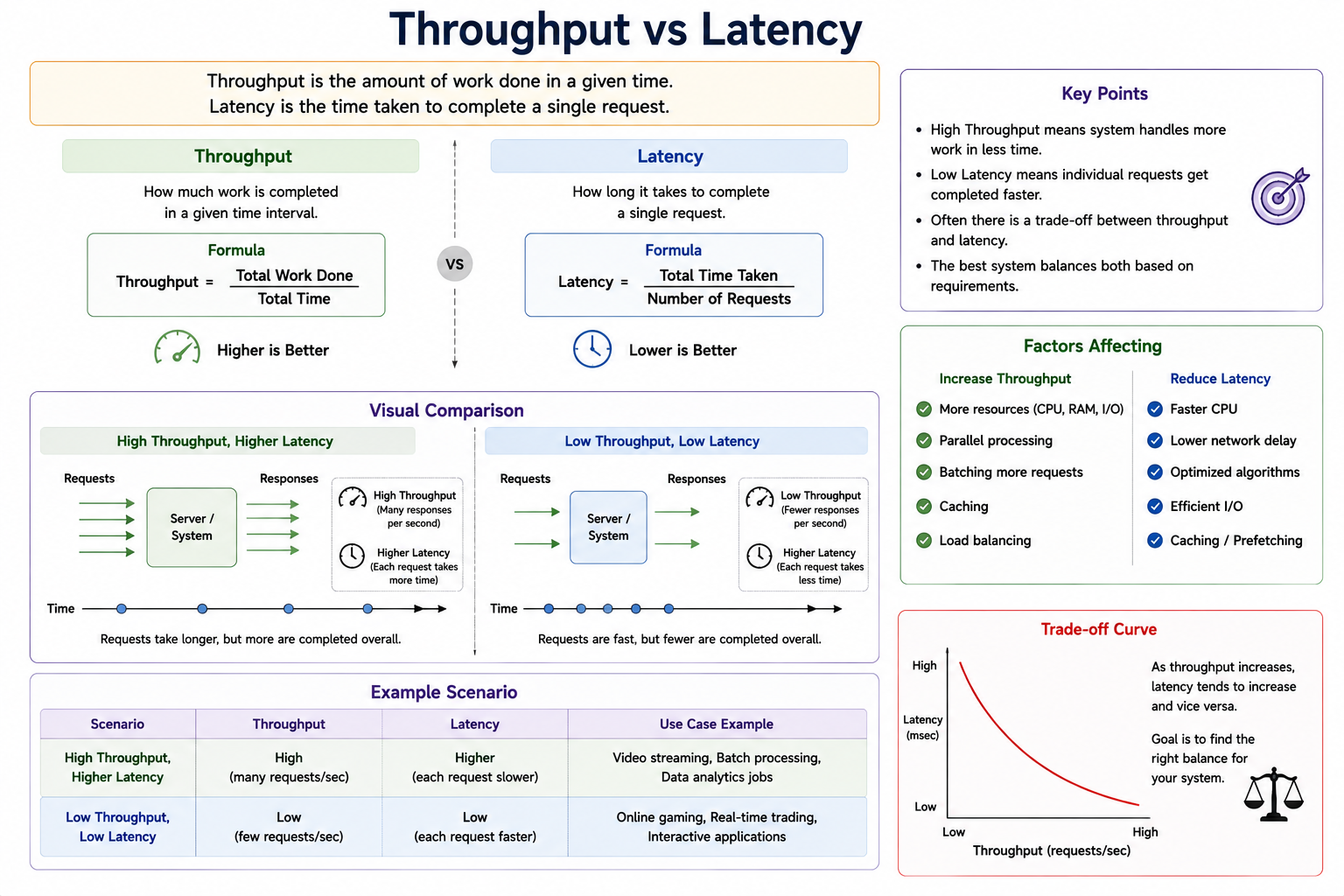
Simple Analogy
Throughput Analogy
A highway carrying:
10,000 cars/hour
has high throughput.
Latency Analogy
Time required for:
One car to reach destination
represents latency.
Important Observation
Highway may:
Carry many cars
Still have long travel delays
Similarly:
High throughput does not guarantee low latency.
Throughput vs Latency Comparison
| Feature | Throughput | Latency |
|---|---|---|
| Measures | Work completed | Time per task |
| Focus | Capacity | Responsiveness |
| Unit | Tasks/sec | Seconds/ms |
| Goal | Maximize | Minimize |
Relationship Between Throughput and Latency
Students often assume:
Higher throughput always means lower latency
This is incorrect.
Example
Suppose server overloaded.
It may:
Process many requests overall
But each request waits longer
Result:
High throughput
High latency
Important Insight
Systems often face trade-offs between maximizing throughput and minimizing latency
Queueing and Waiting Time
Latency often increases because of:
Queueing delays
Suppose:
Requests arrive faster than processing speed
Tasks wait in queue.
This increases:
Response time
Latency
Components of Latency
Total latency often includes:
1. Queueing Delay
Waiting before execution.
2. Processing Time
Actual computation.
3. I/O Delay
Disk/network waiting.
4. Context Switching Delay
CPU scheduling overhead.
5. Transmission Delay
Network transfer time.
Throughput in Operating Systems
Operating systems attempt to maximize throughput by:
Efficient CPU scheduling
Parallel execution
Resource sharing
Multitasking
Example
Linux scheduler tries to:
Keep CPU busy continuously
CPU-Bound vs I/O-Bound Workloads
CPU-Bound
Performance limited by CPU speed.
Examples:
Scientific computing
Video encoding
I/O-Bound
Performance limited by storage/network.
Examples:
Database queries
File servers
Important Insight
System bottlenecks strongly influence both throughput and latency
Throughput Optimization Techniques
1. Parallel Processing
Multiple tasks execute simultaneously.
2. Multicore Processing
Uses multiple CPU cores.
3. Load Balancing
Distributes workload efficiently.
4. Caching
Reduces repeated computation.
5. Batch Processing
Processes tasks in groups.
Latency Optimization Techniques
1. Faster Algorithms
Reduce execution time.
2. Reduced Queueing
Prevent overload.
3. Prioritized Scheduling
Interactive tasks run sooner.
4. Local Caching
Reduce network delays.
5. Edge Computing
Move computation closer to users.
Important Insight
Throughput optimization focuses on capacity, while latency optimization focuses on responsiveness
Throughput and Latency in CPU Scheduling
Throughput Goal
Maximize completed jobs.
Latency Goal
Reduce response time.
Some scheduling algorithms favor:
Throughput
Others favor:
Responsiveness
Example
Batch systems:
High throughput focus
Interactive systems:
Low latency focus
Throughput and Latency in Networking
High Throughput Network
Transfers large amount of data.
Low Latency Network
Very fast response time.
Example
Video streaming:
Throughput important
Online gaming:
Latency critical
Throughput and Latency in Databases
Databases optimize:
Transactions per second (throughput)
Query response time (latency)
Example
Banking system:
Both extremely important
Little’s Law (Important Concept)
Queueing theory relation:
L = \lambda W
Where:
(L) = average number of items in system
(\lambda) = throughput rate
(W) = average waiting time (latency)
This equation connects:
Throughput
Latency
Queue size
Scalability and Throughput
Scalable systems aim to:
Increase throughput as workload grows
Horizontal Scaling
Add more machines.
Vertical Scaling
Increase machine power.
Throughput Collapse
If overload becomes extreme:
Throughput may decrease
due to:
Excessive contention
Queue growth
Context switching overhead
Tail Latency
Modern distributed systems care heavily about:
Tail latency
Example:
99th percentile response time
Reason:
Slowest requests heavily affect user experience.
Important Insight
Modern systems optimize not only average latency but also worst-case latency
Real-World Example: Web Server
Suppose:
100 users access website
Good Throughput
Server handles many requests/sec.
Good Latency
Pages load quickly for each user.
Under Heavy Load
Throughput may remain high while:
Page load times worsen
because:
Queueing increases.
Throughput vs Latency Trade-Off Examples
Batch Processing Systems
Optimize:
Throughput
Less concerned with latency.
Real-Time Systems
Optimize:
Low latency
Even if throughput lower.
Video Streaming
Requires:
Sustained throughput
Autonomous Vehicles
Require:
Extremely low latency
Measuring Throughput and Latency
Throughput Metrics
Requests/sec
MB/sec
Transactions/sec
Latency Metrics
Milliseconds
Microseconds
Percentile delays